How to automate creating high end virtual machines on AWS for data science projects
Posted on Mon 11 September 2017 in tutorial
This is a log of my findings while trying to automate the creation of Virtual Machines on Amazon Web Services.
Last year I started my MSc in Data Science. Anyone who has been on a similar position knows that running Machine Learning algorithms is very resource intensive. You can either spend hours waiting for an algorithm to finish on a regular PC/laptop, spend about $1000 on buying a high-end PC or get a VM on the cloud providers.
Both of the latter two options have their pros and cons that may suit one's needs. I will only focus on the last option here i.e. deploying high end VM on AWS.
The simple way of creating a virtual machine is by using the provider website. AWS has a web console interface for creating resources but it can get time consuming and repetitive to use the interface for one time machines. Furthermore there's a hassle with installing the required software packages everytime (a process called configuration), getting the machine details (public DNS name, public IP etc)
I'll be using the Terraform orchestration tool to quickly set up and configure the required Virtual Machine server as fast as possible to minimize time lost on the trivial activities and maximize the value for the money paid for the server. Finally once I'll be finished with the project I can destroy the Virtual Machine as to stop getting charged for it.
Tech Stack
What will be required:
- The Terraform tool. As mentioned this is the basic tool that will be used for provisioning the Virtual Machines.
- A Unix shell. This guide can probably work with the Windows bash but I haven't tested it.
- An Amazon Web Services account.
What is Infrastructure As Code and what is Terraform?
Infrastructure as code is a new DevOps philosophy where the application infrastructure is no longer created by hand but programmatically. The benefits are numerous including but not limited to: - Speed of deployment - Version Control of Infrastructure - Engineer agnostic infrastructure (no single point of failure/no single person to bug) - Better lifetime management (automatic scale up/down, healing) - Cross-provider deployment with minimal changes
Terraform is a tool that helps in this direction. It is an open source tool developed by Hashicorp.
This tool allows you to write the final state that you wish your infrastructure to have and terraform applies those changes for you.
You can provision VMs, create subnets, assign security groups and pretty much perform any action that any cloud provider allows.
Terraform support a wide range of providers including the big 3 ones AWS, GCP, Microsoft Azure.
Installing Terraform
Terraform is written in Go and is provided as a binary for the major OSs but can also be compiled from source code.
The binary can be downloaded from the Terraform site and does not require any installation. We just need to set it to the path variable (for Linux/macOS instructionscan be found here and for Windows here) so that it is accessible from our system in any path.
After we have this has finished we can confirm that it is ready to be used by running the terraform command and we should get something like the following:
$ terraform
Usage: terraform [--version] [--help] <command> [args]
The available commands for execution are listed below.
The most common, useful commands are shown first, followed by
less common or more advanced commands. If you're just getting
started with Terraform, stick with the common commands. For the
other commands, please read the help and docs before usage.
Common commands:
apply Builds or changes infrastructure
console Interactive console for Terraform interpolations
destroy Destroy Terraform-managed infrastructure
env Environment management
fmt Rewrites config files to canonical format
get Download and install modules for the configuration
graph Create a visual graph of Terraform resources
import Import existing infrastructure into Terraform
init Initialize a new or existing Terraform configuration
output Read an output from a state file
plan Generate and show an execution plan
push Upload this Terraform module to Atlas to run
refresh Update local state file against real resources
show Inspect Terraform state or plan
taint Manually mark a resource for recreation
untaint Manually unmark a resource as tainted
validate Validates the Terraform files
version Prints the Terraform version
All other commands:
debug Debug output management (experimental)
force-unlock Manually unlock the terraform state
state Advanced state management
Now we can move on the using the tool.
Setting up the AWS account
This is a step that is not specific to this project but rather it's something that needs to be configured whenever a new AWS account is set up. When we create a new account with Amazon, the default account we are given has root access to any action. Similarly with the linux root user we do not want to be using this account for the day-to-day actions, so we need to create a new user.
We navigate to the Identity and Access Management (IAM) page, click on Users, then the Add user button. We provide the User name, and click the Programmatic access checkbox so that an access key ID and a secret access key will be generated.
Clicking next we are asked to provide a Security Group that this User will belong to. Security Groups are the main way to provide permission and restrict access to specific actions required. For this purpose of this project we will give the AdministratorAccess permission to this user, however when used in a professional setting it is advised to only allow permissions that a user needs (like AmazonEC2FullAccess if a user will only be creating EC2 instances).
Finishing the review step Amazon will provide the Access key ID and Secret access key. We will provide these to terraform to grant it access to create the resources for us. We need to keep these as they are only provided once and cannot be retrieved (however we can always create a new pair).
The secure way to store these credentials as recommended by Amazon is keeping them in a hidden folder under a file called credentials. This file can be accessed by terraform to retrieve them.
$ cd
$ mkdir .aws
$ cd .aws
~/.aws$ vim credentials
We add the following to the credentials file after replacing ACCESS_KEY and SECRET_KEY and then save it:
[default]
aws_access_key_id = ACCESS_KEY
aws_secret_access_key = SECRET_KEY
We also restrict access to this file only to the current user:
~/.aws$ chmod 600 credentials
Setting up a key pair
The next step is to create a key pair so that terraform can access the newly created VMS. Notice that this is different than the above credentials. The Amazon credentials are for accessing and allowing the AWS service to create the resources required, while this key pair will be used for accessing the newly created Virtual Machines.
Log into the AWS console and select Create Key Pair. Add a name (I name mine mac-ssh) and click Create. AWS will create a .pem file and download it locally.
Move this file to the .aws directory. Notice the name of the file to move will be different based on the name provided while creating the file.
~/Downloads$ cd ~/Downloads && mv mac-ssh.pem ../.aws/
Then restrict the permissions:
$ cd ../.aws && chmod 400 mac-ssh.pem
Now we ready to use this key pair either via a direct ssh to our instances, or for terraform to use this to connect to the instances and run some scripts.
Provisioning VMs & Configuring Them
So now that everything is set up, we can move to actually creating the virtual machines.
Let's create a new folder called terraform.
$ mkdir terraform
$ cd terraform
In that folder we will create two files one called main.tf and the second configure.sh. The first file is the terraform specific code that handles the creation of the Virtual Machine. The second file is a bash script that will be run on the created machine to configure it with the software required.
So this is the main.tf file:
provider "aws" {
region = "eu-west-1"
version = "~> 0.1"
}
resource "aws_security_group" "jupyter_notebook_sg" {
name = "jupyter_notebook_sg"
# Open up incoming ssh port
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
# Open up incoming traffic to port 8888 used by Jupyter Notebook
ingress {
from_port = 8888
to_port = 8888
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
# Open up outbound internet access
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
resource "aws_instance" "Node" {
count = 1
ami = "ami-a8d2d7ce"
instance_type = "m4.xlarge"
key_name = "mac-ssh"
tags {
Name = "Jupyter Notebook Meganode"
}
vpc_security_group_ids = ["${aws_security_group.jupyter_notebook_sg.id}"]
provisioner "file" {
source = "configure.sh"
destination = "/tmp/configure.sh"
connection {
type = "ssh"
user = "ubuntu"
private_key = "${file("~/.aws/mac-ssh.pem")}"
}
}
provisioner "remote-exec" {
inline = [
"chmod +x /tmp/configure.sh",
"/tmp/configure.sh",
]
connection {
type = "ssh"
user = "ubuntu"
private_key = "${file("~/.aws/mac-ssh.pem")}"
}
}
}
output "node_dns_name" {
value = "${aws_instance.Node.public_dns}"
}
And this the configure.sh:
!#/bin/bash
sudo apt-get update
sudo apt-get -y install git
sudo apt-get -y install vim
sudo apt-get -y install python3 python3-pip python3-dev
sudo -H pip3 install jupyter
mkdir ~/.jupyter
echo "c.NotebookApp.allow_origin = '*'
c.NotebookApp.ip = '0.0.0.0'" | sudo tee /home/ubuntu/.jupyter/jupyter_notebook_config.py
Let's break down the terraform blueprint. We start by defining the provider:
provider "aws" {
region = "eu-west-1"
version = "~> 0.1"
}
Terraform defines these blocks contained within the curly braces. The first word is usually a reserved word that defines something in this case the provider that will be used in this blueprint. The next word again is a reserved word but it's provider specific. Blocks can have a third word which is usually an identifier, like a variable to reference the specific resource whithin another block. Regarding the first block, the core Terraform software is provider agnostic so each blueprint needs to define the provider on which the resources will be created at. You can find all the supported providers here. You can find all the AWS specific details here. The region value is basically the AWS datacenter on which the Virtaul Machine will be created at. You can find all available regions here. It's generally advised to pick the one that is closest to you as to minimize the response time between your PC and the Virtual Machine. Finally the version value is referring to the version of the AWS plugin that will be used.
The next block defines the first resource that will be created.
resource "aws_security_group" "jupyter_notebook_sg" {
name = "jupyter_notebook_sg"
# Open up incoming ssh port
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
# Open up incoming traffic to port 8888 used by Jupyter Notebook
ingress {
from_port = 8888
to_port = 8888
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
# Open up outbound internet access
egress {
from_port = 0
to_port = 0
protocol = "-1"
cidr_blocks = ["0.0.0.0/0"]
}
}
It can be considered like a virtual firewall that allows or restricts incoming and outgoing traffic to VMs. You can assign more than one security groups in a VM. In this can we have created three rules. We have allowed incoming traffic (ingress) to ports 22 and 8888 which are used for ssh access and by jupyter notebook respectively from any IP address. The last rule allows outgoing (egress) traffic from all IPs, to all ports, with any protocol.
Finally note that as mentioned in the previous paragraph, the block declaration starts with the resource word, followed by the type of resource the block defines (here aws_security_group), and we give the name jupyter_notebook_sg to this resource. We will see how we use this in the next block. You can read more about security groups here.
The third block is the one that defines the Virtual Machine resource.
resource "aws_instance" "Node" {
count = 1
ami = "ami-a8d2d7ce"
instance_type = "m4.xlarge"
key_name = "mac-ssh"
tags {
Name = "Jupyter Notebook Meganode"
}
vpc_security_group_ids = ["${aws_security_group.jupyter_notebook_sg.id}"]
provisioner "file" {
source = "configure.sh"
destination = "/tmp/configure.sh"
connection {
type = "ssh"
user = "ubuntu"
private_key = "${file("~/.aws/mac-ssh.pem")}"
}
}
provisioner "remote-exec" {
inline = [
"chmod +x /tmp/configure.sh",
"/tmp/configure.sh",
]
connection {
type = "ssh"
user = "ubuntu"
private_key = "${file("~/.aws/mac-ssh.pem")}"
}
}
}
As above, we define the resource type we want to create (aws_instance) and we give the name Node to this resource. Notice that this name is only used by Terraform it is not something that is defined in AWS.
The first value that need defining is the ami (count is pretty self explanatory so I skip it). This stands for Amazon Machine Image. Basically it's the image of the Operating System that will be installed on the created VM. The way to find this ami value is described by Amazon here. There are countless images to choose from with many software packages preinstalled to choose from. However this can get a bit chaotic is you are just looking for a simple generic OS image. I have picked the AMI for the ubuntu 16.04 server image.
I prefer to find the ami from the launch EC2 instance wizard that AWS provides, it's clearer for the base OS images.
Next we define the instance_type. This is the type of Virtual Machine that will be created. You can find all the different instance types here along with the pricing. The one I picked here is the m4.xlarge instance which has 4 virtual CPUs, 16 GB of RAM and costs about $0.2 per hour at the time of writing, however this price is usually variant on the region.
Tags are AWS specific details, here we provide a Name for the VM.
Next we provide a list of vpc_security_group_ids which are the AWS ids Security Groups, we have only provided one in this case, the one we created.
Finally the last two blocks are using another Terraform block type, the provisioner. Provisioners are used to execute scripts on a local or remote machine as part of resource creation or destruction. Provisioners can be used to bootstrap a resource, cleanup before destroy, run configuration management, etc.
The first provisioner is a file provisioner which copies files to the resource (we use it to copy the configure.sh script we created), while the second one remote-exec runs a shell command on the VM once it has been created (we make the script executable and then run it). Both provisioner use another block called connection which defines the connection type and the credentials required to reach the VM.
Finally Terraform defines a way to extract details from the created resources using the output block.
output "node_dns_name" {
value = "${aws_instance.Node.public_dns}"
}
We will use this to output the VM public DNS name so that we can access the machine easily.
This was a pretty rough introduction to the basics of Terraform that were used but I urge you to read the official documentation to learn more about it.
The configuration script is really basic:
!#/bin/bash
sudo apt-get update
sudo apt-get -y install git
sudo apt-get -y install vim
sudo apt-get -y install python3 python3-pip python3-dev
sudo -H pip3 install jupyter
mkdir ~/.jupyter
echo "c.NotebookApp.allow_origin = '*'
c.NotebookApp.ip = '0.0.0.0'" | sudo tee /home/ubuntu/.jupyter/jupyter_notebook_config.py
We run a system update, then install git, vim, python3 and python3 pip, and the jupyter notebook. The last 3 lines are of interest as they create the jupyter notebook specific configuration file, and assigns values to allow_origin and ip which allow access to the notebook from any server.
Of course you can add any other packages you which your VM to have on this script.
Now that the blueprint is explained we are ready to run it. The first time we run terraform with any blueprint we to initialize it. We do that by running:
$ terraform init
This way Terraform will try to find the relevant provider plugin required for this blueprint and download it.
And now we are ready to create the VM. Let's start by running terraform plan:
$ terraform plan
Refreshing Terraform state in-memory prior to plan...
The refreshed state will be used to calculate this plan, but will not be
persisted to local or remote state storage.
The Terraform execution plan has been generated and is shown below.
Resources are shown in alphabetical order for quick scanning. Green resources
will be created (or destroyed and then created if an existing resource
exists), yellow resources are being changed in-place, and red resources
will be destroyed. Cyan entries are data sources to be read.
Note: You didn't specify an "-out" parameter to save this plan, so when
"apply" is called, Terraform can't guarantee this is what will execute.
+ aws_instance.Node
ami: "ami-785db401"
associate_public_ip_address: "<computed>"
availability_zone: "<computed>"
ebs_block_device.#: "<computed>"
ephemeral_block_device.#: "<computed>"
instance_state: "<computed>"
instance_type: "t2.micro"
ipv6_address_count: "<computed>"
ipv6_addresses.#: "<computed>"
key_name: "mac-ssh"
network_interface.#: "<computed>"
network_interface_id: "<computed>"
placement_group: "<computed>"
primary_network_interface_id: "<computed>"
private_dns: "<computed>"
private_ip: "<computed>"
public_dns: "<computed>"
public_ip: "<computed>"
root_block_device.#: "<computed>"
security_groups.#: "<computed>"
source_dest_check: "true"
subnet_id: "<computed>"
tags.%: "1"
tags.Name: "Jupyter Notebook Meganode"
tenancy: "<computed>"
volume_tags.%: "<computed>"
vpc_security_group_ids.#: "<computed>"
+ aws_security_group.jupyter_notebook_sg
description: "Managed by Terraform"
egress.#: "1"
egress.482069346.cidr_blocks.#: "1"
egress.482069346.cidr_blocks.0: "0.0.0.0/0"
egress.482069346.from_port: "0"
egress.482069346.ipv6_cidr_blocks.#: "0"
egress.482069346.prefix_list_ids.#: "0"
egress.482069346.protocol: "-1"
egress.482069346.security_groups.#: "0"
egress.482069346.self: "false"
egress.482069346.to_port: "0"
ingress.#: "2"
ingress.2541437006.cidr_blocks.#: "1"
ingress.2541437006.cidr_blocks.0: "0.0.0.0/0"
ingress.2541437006.from_port: "22"
ingress.2541437006.ipv6_cidr_blocks.#: "0"
ingress.2541437006.protocol: "tcp"
ingress.2541437006.security_groups.#: "0"
ingress.2541437006.self: "false"
ingress.2541437006.to_port: "22"
ingress.433339597.cidr_blocks.#: "1"
ingress.433339597.cidr_blocks.0: "0.0.0.0/0"
ingress.433339597.from_port: "8888"
ingress.433339597.ipv6_cidr_blocks.#: "0"
ingress.433339597.protocol: "tcp"
ingress.433339597.security_groups.#: "0"
ingress.433339597.self: "false"
ingress.433339597.to_port: "8888"
name: "jupyter_notebook_sg"
owner_id: "<computed>"
vpc_id: "<computed>"
Plan: 2 to add, 0 to change, 0 to destroy.
Terraform will output what resources will be created so that you can double check that everything is as required. Then we actually run the terraform apply and the resource creation begins:
$ terraform apply
aws_security_group.jupyter_notebook_sg: Creating...
description: "" => "Managed by Terraform"
egress.#: "" => "1"
egress.482069346.cidr_blocks.#: "" => "1"
egress.482069346.cidr_blocks.0: "" => "0.0.0.0/0"
egress.482069346.from_port: "" => "0"
egress.482069346.ipv6_cidr_blocks.#: "" => "0"
egress.482069346.prefix_list_ids.#: "" => "0"
egress.482069346.protocol: "" => "-1"
egress.482069346.security_groups.#: "" => "0"
egress.482069346.self: "" => "false"
egress.482069346.to_port: "" => "0"
ingress.#: "" => "2"
ingress.2541437006.cidr_blocks.#: "" => "1"
ingress.2541437006.cidr_blocks.0: "" => "0.0.0.0/0"
...
...
...
aws_instance.Node: Creation complete after 1m13s (ID: i-05a88fcd8cafae195)
Apply complete! Resources: 2 added, 0 changed, 0 destroyed.
Outputs:
node_dns_name = ec2-34-240-28-230.eu-west-1.compute.amazonaws.com
After a while the resources have been created, we can see that Terraform has provided the public DNS name as mentioned, and we can ssh to the machine:
$ ssh -i ~/.aws/mac-ssh.pem [email protected]
Welcome to Ubuntu 16.04.2 LTS (GNU/Linux 4.4.0-1022-aws x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
Get cloud support with Ubuntu Advantage Cloud Guest:
http://www.ubuntu.com/business/services/cloud
36 packages can be updated.
9 updates are security updates.
Last login: Mon Sep 11 21:08:07 2017 from 141.237.148.33
ubuntu@ip-172-31-45-252:~$
We are ready to start the Jupyter Notebook:
ubuntu@ip-172-31-45-252:~$ jupyter notebook
[I 21:11:32.984 NotebookApp] Writing notebook server cookie secret to /run/user/1000/jupyter/notebook_cookie_secret
[I 21:11:33.006 NotebookApp] Serving notebooks from local directory: /home/ubuntu
[I 21:11:33.006 NotebookApp] 0 active kernels
[I 21:11:33.007 NotebookApp] The Jupyter Notebook is running at: http://0.0.0.0:8888/?token=5cefea05e76d542e73d440f4f2085b536687ecd92adf5552
[I 21:11:33.007 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[W 21:11:33.007 NotebookApp] No web browser found: could not locate runnable browser.
[C 21:11:33.007 NotebookApp]
Copy/paste this URL into your browser when you connect for the first time,
to login with a token:
http://0.0.0.0:8888/?token=5cefea05e76d542e73d440f4f2085b536687ecd92adf5552
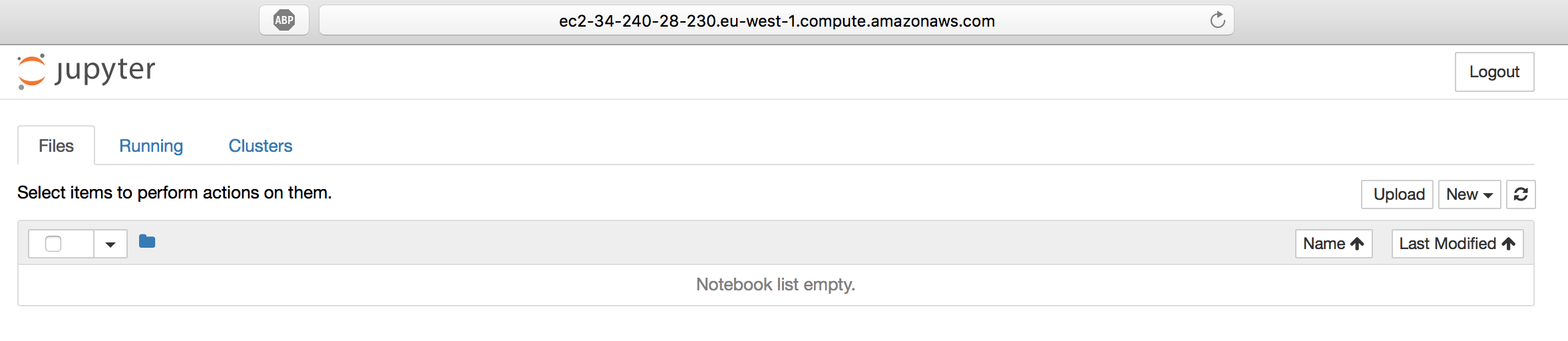
Once it has started Jupyter provides a URL to access it, however we need to substitute the wildcard 0.0.0.0 IP with the machine DNS name so in this case the URL to access the Notebook will be http://ec2-34-240-28-230.eu-west-1.compute.amazonaws.com:8888/?token=5cefea05e76d542e73d440f4f2085b536687ecd92adf5552.
Going to this URL confirms that everything is up and running!
Once we are done with our work we can just destroy the VM. Terraform will ask to confirm the destruction of the VM and then proceed to destroy it.
$ terraform destroy
aws_security_group.jupyter_notebook_sg: Refreshing state... (ID: sg-a19bc7d9)
aws_instance.Node: Refreshing state... (ID: i-05a88fcd8cafae195)
The Terraform destroy plan has been generated and is shown below.
Resources are shown in alphabetical order for quick scanning.
Resources shown in red will be destroyed.
- aws_instance.Node
- aws_security_group.jupyter_notebook_sg
Do you really want to destroy?
Terraform will delete all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
aws_instance.Node: Destroying... (ID: i-05a88fcd8cafae195)
aws_instance.Node: Still destroying... (ID: i-05a88fcd8cafae195, 10s elapsed)
aws_instance.Node: Still destroying... (ID: i-05a88fcd8cafae195, 20s elapsed)
aws_instance.Node: Still destroying... (ID: i-05a88fcd8cafae195, 30s elapsed)
aws_instance.Node: Still destroying... (ID: i-05a88fcd8cafae195, 40s elapsed)
aws_instance.Node: Still destroying... (ID: i-05a88fcd8cafae195, 50s elapsed)
aws_instance.Node: Still destroying... (ID: i-05a88fcd8cafae195, 1m0s elapsed)
aws_instance.Node: Destruction complete after 1m3s
aws_security_group.jupyter_notebook_sg: Destroying... (ID: sg-a19bc7d9)
aws_security_group.jupyter_notebook_sg: Destruction complete after 1s
Destroy complete! Resources: 2 destroyed.
Conclusion
Hope you liked this tutorial. I tried to summarize everything I learned along the way. Terraform is a very helpful tool that is being adopted by many tech companies. After this introduction I would encourage you to read more about it. Creating a single machine is just a very simple case but if you get the hang of you can create multi node architecture with big data systems like Hadoop, Spark etc.
If you have any remarks, bugs, suggestions etc feel free to contact me or leave a comment.